


Kafka 是一个高性能的消息队列中间件,在实际工作中会经常接触到 Kafka,本文主要总结了 Kafka 的常见应用场景,以及 Kafka 作为一个依赖服务,需要考虑哪些测试点。
Kafka 简介:
Apache Kafka 是一个分布式、高吞吐量、低延迟的发布-订阅消息系统,最初由 LinkedIn 开发,后成为 Apache 顶级开源项目。其核心设计目标是实现高效的数据流处理,支持大规模实时数据传输和持久化存储,适用于日志收集、消息队列、流处理等场景。
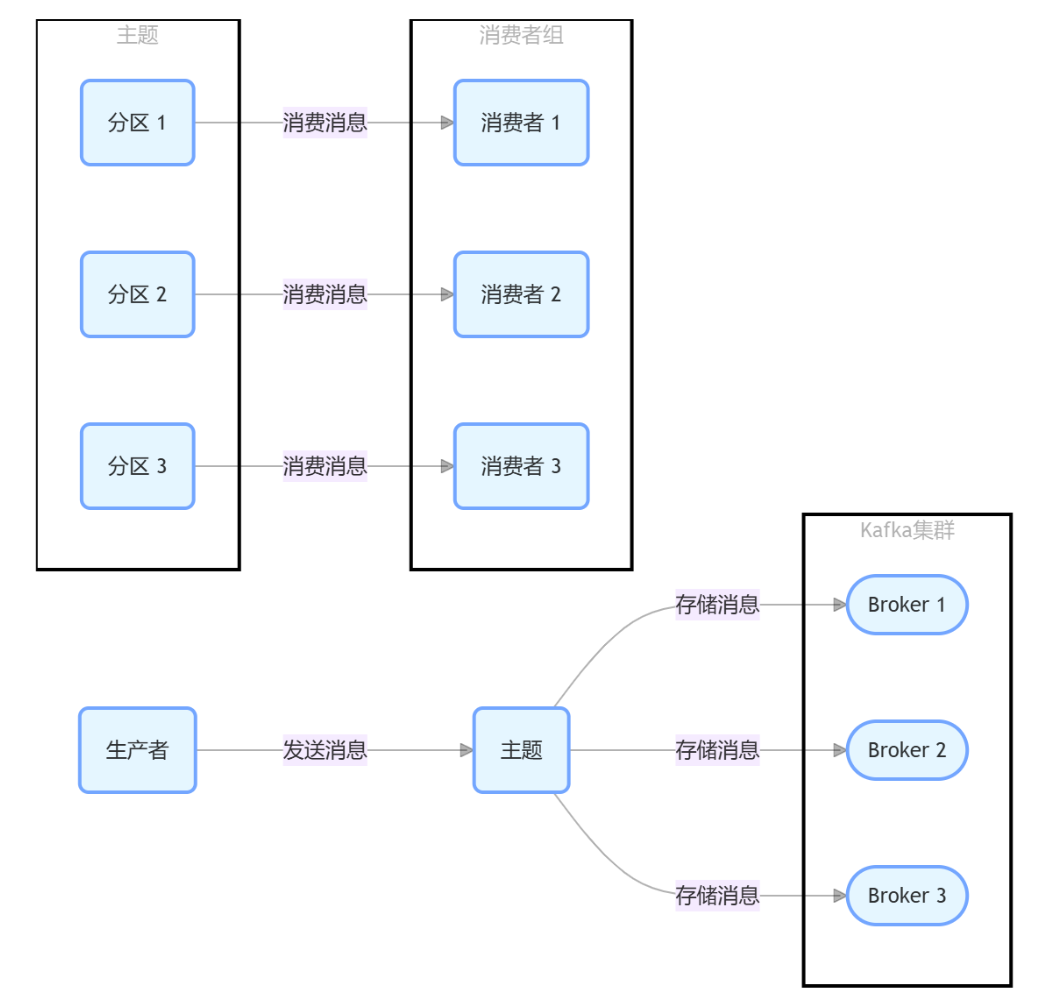
Kafka 的核心组件:
主题(Topic):是 Kafka 中消息的逻辑分类,生产者将消息发送到特定的主题,消费者从主题中读取消息。
分区(Partition):每个主题可以被分成多个分区,分区是 Kafka 实现高吞吐量和可扩展性的关键。每个分区是一个有序的、不可变的消息序列,消息在分区中按照追加的顺序存储。分区可以分布在不同的 Broker 上,实现数据的分布式存储。
生产者(Producer):负责将消息发送到 Kafka 的主题中。生产者可以选择将消息发送到特定分区,也可以让 Kafka 根据消息的键(Key)或者随机分配的方式将消息路由到分区中。
消费者(Consumer):从 Kafka 的主题中读取消息。消费者通常以消费者组(Consumer Group)的形式存在,一个主题中的消息可以被一个消费者组中的多个消费者消费,每个分区的消息只能由消费者组中的一个消费者消费,实现消息的并行处理。
代理(Broker):是 Kafka 集群中的一个节点,负责存储和管理分区的数据。多个 Broker 可以形成一个 Kafka 集群,集群中的每个 Broker 可以存储多个分区的数据。
Kafka 的应用场景:
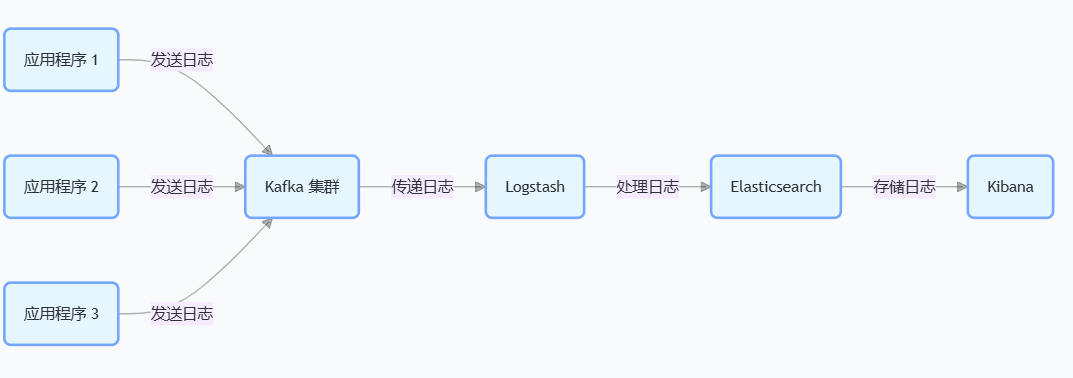
日志收集:将各个应用程序的日志收集到 Kafka 中,然后由日志分析工具,进行处理分析和可视化(如 Lostash + Elasticsearch + Kibana)。
消息队列:作为消息队列实现不同服务之间的异步通信,例如微服务架构中服务之间的解耦和通信。
Kafka 的使用demo:
生产者:
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerEg {
public static void main(String[] args) {
// 配置 Kafka 生产者的属性
Properties props = new Properties();
// 指定 Kafka 集群的地址
props.put("bootstrap.servers", "localhost:9092");
// 指定消息的序列化器
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建 Kafka 生产者实例
Producer<String, String> producer = new KafkaProducer<>(props);
// 要发送的主题名称
String topic = "test_topic";
// 发送 10 条消息
for (int i = 0; i < 10; i++) {
String key = "Key-" + i;
String value = "Message-" + i;
// 创建消息记录
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
// 发送消息并处理发送结果
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.err.println("Failed to send message: " + exception.getMessage());
} else {
System.out.printf("Sent message: key = %s, value = %s, partition = %d, offset = %d%n",
key, value, metadata.partition(), metadata.offset());
}
}
});
}
// 关闭生产者连接
producer.close();
}
}消费者:
import org.apache.kafka.clients.consumer.*;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerEg {
public static void main(String[] args) {
// 配置 Kafka 消费者的属性
Properties props = new Properties();
// 指定 Kafka 集群的地址
props.put("bootstrap.servers", "localhost:9092");
// 指定消费者组 ID
props.put("group.id", "test_group");
// 指定消息的反序列化器
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 自动提交偏移量
props.put("enable.auto.commit", "true");
// 自动提交偏移量的时间间隔
props.put("auto.commit.interval.ms", "1000");
// 创建 Kafka 消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅主题
String topic = "test_topic";
consumer.subscribe(Collections.singletonList(topic));
try {
while (true) {
// 拉取消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
// 处理拉取到的消息
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Received message: key = %s, value = %s, partition = %d, offset = %d%n",
record.key(), record.value(), record.partition(), record.offset());
}
}
} finally {
// 关闭消费者连接
consumer.close();
}
}
}Kafka 测试策略:
功能点:
验证 topic 的正确性
验证生产者服务消息发布的过程
验证消费者服务消息消费的过程
正向的用例demo:
用例名:Kafka 的消息消费
前置步骤:请求生产者服务的对外接口,构建消息数据A
操作步骤:请求消费者服务的消费接口
期望值:请求消费者服务的相关查询接口查询消费情况,找到结果关键字是否 == 数据A
逆向的用例场景:在没有发布消息的情况下,请求消费者服务的消费接口,有没有进行正常的处理,如果消费者对外接口出现 loading 情况,说明未对该场景进行处理。
性能点:
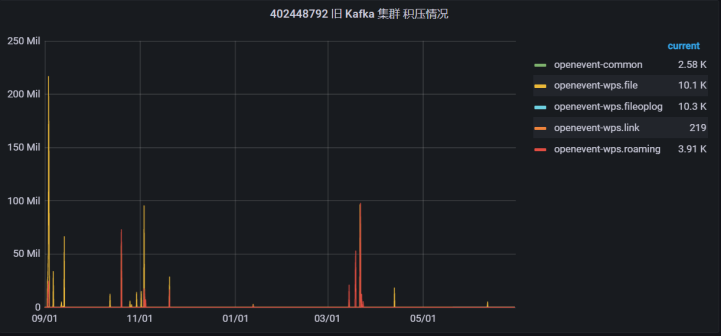
模拟消息积压的场景。获取到的结果:1. 消费者的消费的速率,可以满足多少的并发数不会出现消息积压的情况。2. 生产者基于外部接口的消息生产速率。3. broker 是否支撑目前的消息积压情况。
Kafka 监控平台一般只能提供有哪些 topic,每个 topic 当前消息积压的情况。
评论区